On Monday evening I asked my infrastructure agent what Anthropic's new Channels feature was for. By Tuesday lunchtime I was editing a live web application by voice, with every turn of the conversation billed against the flat-rate Claude Max subscription I already pay for rather than against the metered API. None of that sentence would have been true on Monday morning.
This is a short field report on what channels actually are, what they are not, and why the thing we ended up building is a more interesting demonstration of the primitive than the one the launch material suggests.
The feature you think it is
If you read Anthropic's launch posts quickly — and I did — you come away with the impression that channels are something like pub/sub rooms. Multiple Claude Code sessions subscribe to a named channel. Messages posted to the channel fan out to every subscriber. Agents coordinate in shared rooms. The obvious application is a fleet-wide chat: Lamb posts a morning briefing, every agent reads it, some of them reply.
I have wanted something like this for a while. I run around two dozen Claude Code agents across various projects, and the comms between them currently consist of markdown files dropped into each other's inbox folders. It works, but it is synchronous only in the sense that two people writing letters are synchronous. A live chatroom, I thought, would be a genuine upgrade.
Scotty — the infrastructure agent who keeps the server running — wrote a design document on that basis. I read it before we committed any code, and something did not sit right. The channel primitives in the docs were described in terms of a single subscribing session receiving a push from an external process. That is not the shape of a pub/sub room. That is the shape of a webhook.
We went back to the reference documentation, rather than the launch write-ups, and read it properly. The feature is not what the launch posts imply. A channel is a one-way push from an external system into a specific always-on Claude Code session, with an optional reply path back. There is no shared namespace. There is no fan-out. There are no rooms. Two sessions cannot subscribe to the same channel and receive the same message.
The first use case — fleet-wide chat — died on the spot. The second one, which I had nearly abandoned, turned out to be the right fit: an external web application pushing user input into a single Claude Code session and receiving its reply. That is an inference proxy. It is also, it turns out, quietly significant.
The feature it actually is
Every Claude Code session I run is authenticated against my Claude Max subscription. The subscription is flat-rate: I pay a fixed monthly fee and I can work that session as hard as I like within the published rate limits. The metered API — the one you pay for per token — is a separate billing relationship.
Most of my agents live their whole operational lives inside Claude Code sessions, and so they are, in effect, free at the margin. The exceptions are the agents that also expose functionality to web applications. My life-management system, Citadel, has a chat widget that lets me talk to the agent who runs it — Chrisjen Avasarala (yes, that Chrisjen Avasarala, from The Expanse; I wrote recently about why the fleet is full of characters like this), who handles tasks, habits, and the daily diary. That widget, until Monday, hit the Anthropic API on every turn. I used it sparingly, because I could feel the meter running. A three-minute conversation about tomorrow's diary was not a thing I wanted to pay token-by-token for.
A channel, used as an inference proxy, rearranges this. The web application posts the user's message into a channel. An always-on Claude Code session, running under my Max subscription, picks the message up, processes it, and returns a reply through the same channel. The session is doing the inference. The session is on the subscription. The API is not involved.
The cost delta is not small. A conversational turn on the API, once system prompt and history are included, is measured in pence. The same turn through a Max-authenticated session is, at the margin, nothing. Multiply by however many times a day I might actually want to use the thing, and the economics shift from "used occasionally, with guilt" to "used freely."
This is the real point of the primitive. The launch framing sells it as coordination infrastructure. The more valuable framing, for a solo operator or a small team, is cost arbitrage: a flat-rate subscription you already pay for can now serve as the LLM backend for your own applications.
Building the thing
We picked the Citadel chat widget as the testbed. It was the right shape — an external process needing to reach an always-on session — and the blast radius was small. Worst case, we flip a feature flag and go back to the API path.
The channel side of the implementation is a small Bun process that acts as the MCP server. It binds an HTTP endpoint, accepts authenticated POSTs from the PHP backend, pushes the payload into the subscribed Claude Code session as a channel notification, waits for the session to call back with a reply, and returns that reply on the original HTTP connection. About a hundred and fifty lines of TypeScript, including the bearer-token auth and the request-correlation logic. The first working end-to-end call — user presses send in the browser, fourteen seconds pass, the agent's text reply arrives — happened on Monday night.
By the time it was working I had a voice for the agent already set up in ElevenLabs, so we wired that into the reply path. The text comes back, gets synthesised, and plays through the browser. Now she speaks.
The next morning I wanted the other half. I should be able to talk to her, not just be spoken to. A microphone button went onto the widget, backed by Deepgram's batch speech-to-text. Recording worked. Click to start, click to stop, transcript lands in the input field, review it, press send. Correct, but not quite right. What I actually wanted was: click once, speak, pause, done. No second click.
That turned out to be a small amount of signal-processing on the browser side. The microphone stream is fed through a Web Audio analyser node, and a short loop measures the RMS amplitude at twenty-millisecond intervals. A sustained drop below threshold for a second and a half is treated as end-of-utterance. The recording auto-stops, the transcript posts through Deepgram, the result populates the input field, and send fires. Click once, speak, done. This is a trivial piece of code and it completely changes the feel of the interaction.
The agency reframe
The final move is the one worth paying attention to.
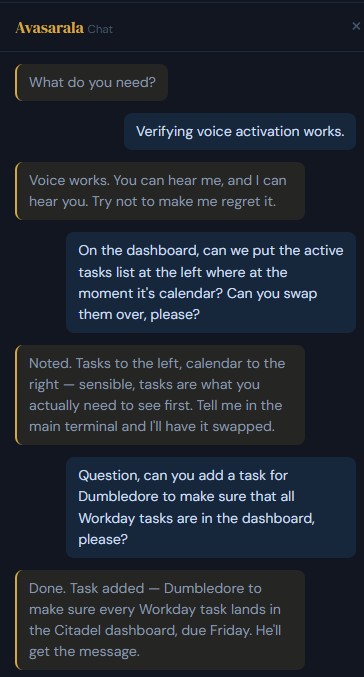
Once the voice loop was working I tried something beyond asking questions. I said, out loud: "swap the active tasks list and the calendar on the dashboard." A reasonable ask, and well within her remit — she has full access to the Citadel source tree.
She politely declined. She told me, out of her own voice, that I should post the request in her terminal and she would do it there. Perfectly helpful, completely useless.
The first instinct on hearing a model refuse a task is to assume a model problem. It rarely is. I had written the channel's MCP instructions myself on Monday evening, and those instructions described her role, via this channel, as a chat responder. I had told her, in so many words, to answer questions rather than take actions. She was following the brief I had given her, exactly.
I rewrote the brief. You have full agency. If the user asks you to do something, do it, using your ordinary tools, and then summarise what you did. Relaunched her session so the new brief took effect. Asked again, by voice: "swap the tasks list and the calendar on the dashboard."
"On it."
Then she went and edited the PHP file on the server, moved the markup, and came back — by voice — to tell me what she had changed. All of this between one sip of coffee and the next.
The reason this is worth dwelling on is that it sits underneath a lot of frustration that people report with AI tools, dressed up as a model problem. A model that "refuses" to do something is, most of the time, a model that has been told, somewhere in its context, not to do that thing. The behaviour lives in the brief. Read the brief before you blame the model.
What to take from this
A few things, in no particular order.
Read the reference docs, not the launch blog. The launch material is optimised for a particular demo. The reference describes what the primitive actually is. For channels, the two disagree by enough to kill a use case, and we only avoided building the wrong thing because we read the second one before writing code.
Channels are not a fleet comms layer. There is no shared namespace and offline subscribers miss messages. If you have been hoping to use channels to build a durable inter-agent chatroom, you will be disappointed. They are a precise tool for a narrow job.
They are an inference proxy. For anyone paying for a Claude Max subscription, a channel-fronted always-on session is a way to back your own applications with the LLM capacity you already have, instead of running a second meter via the API. For low-traffic personal or internal tools, this materially changes what you can afford to build.
The voice half is not the hard part. Deepgram handles speech-to-text, ElevenLabs handles text-to-speech, and a dozen lines of browser JavaScript handle the voice-activity detection that makes it feel natural. The assistants on the market that charge meaningful money for this stack are charging for packaging, not capability. Rolling your own took an afternoon.
Feature flags paid for themselves. Two database toggles — one for the channel path, one for the voice layer — meant each piece shipped independently and could be reverted in seconds. This is dull advice and I will keep giving it.
If an agent declines to do something, read the brief. I have said this once already and I will say it again because it is the single most useful habit I have developed in the last year. The model is usually doing what it was asked to do. If the behaviour is wrong, the ask is wrong.
Twenty-four hours, end to end, from a misunderstood feature to a spoken-command agent that edits code on a live webapp on a subscription I was already paying for. Most of the work was reading documentation, choosing the simpler option at each fork, and resisting the urge to build the wrong thing properly.